Background and Motivation
Currently we keep the EVE device networking and the different network instances for application networking separated using a combination of ip rules (PBR = policy based routing) and ACLs (iptables).
...
The following drawing visually depict the current EVE implementation with an example of 4 apps, 2 local NIs, one switch NI and some (non-overlapping) IP addressing ("NI" is abbreviation we use for "network instance"):
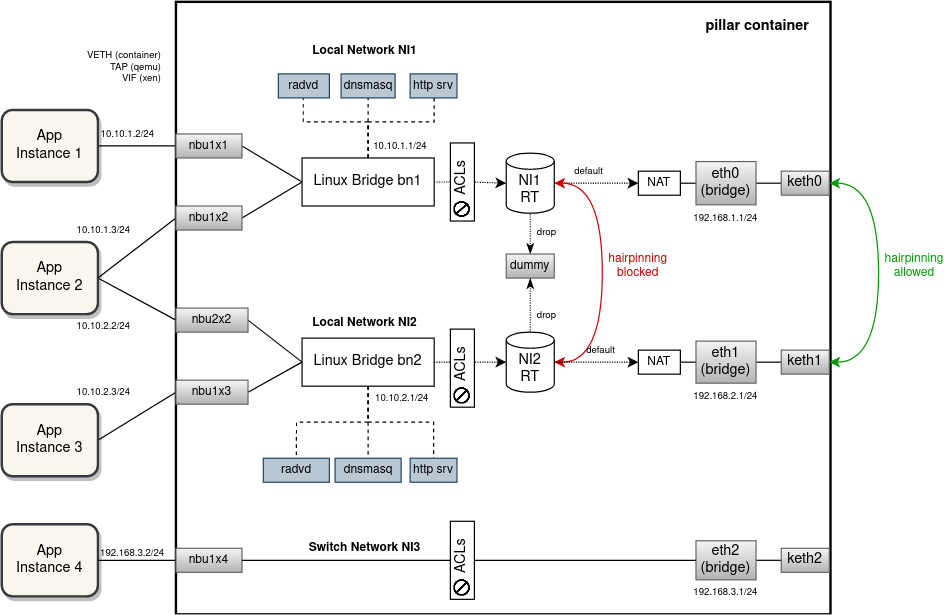
Note that the ACLs are mostly implemented on the network-instance side to provide drop and rate limiting, and also to mark packets for flowlog. There are a few iptables rules on the uplink (right) side to block some TCP/UDP ports from remote access etc.
While the current implementation is successful in prohibiting a direct communication between network instances and facilitating hairpinning inside or outside the device based on the aforementioned criteria, it fails to isolate networks when it comes to IP address allocation.
...
We can get better isolation, including IP address isolation if we split network instances using either VRFs or with network namespaces. Furthemore, if we use a containerd task to run network instance networking (especially the external processes like dnsmasq, radvd, etc.), we can even isolate resource usage and apply limiting. We will now describe VRFs and network instances separately, with a bit more focus on VRFs, which, after some internal discussion, is now the preferred choice.
VRFs
VRF device combined with IP rules provides the ability to create virtual routing and forwarding domains (aka VRFs, VRF-lite to be specific) in the Linux network stack. VRF essentially provides a light-weight L3-level (and above) isolation, i.e. multiple interfaces can have the same IP address assigned if they are inside different VRF domains and, similarly, multiple processes can listen on the same IP address. Compare that with network namespaces, which provide a full device-level isolation, but at a cost of a higher overhead and with additional challenges for the management plane (see "Network Namespaces" below).
VRF is implemented as just another type of network device that can be created and described using the ip command. For every VRF, there is a separate routing table automatically created together with a special IP rule, matching packet with the corresponding VRF routing table. For an interface to enter a VRF domain, it has to be enslaved under the VRF device (just like interfaces are enslaved under a bridge). The main drawback of VRFs is that processes have to explicitly bind their sockets to the VRF in which they want to operate. This, however, can be solved outside of those processes by hooking up into the socket() function call using LD_PRELOAD. Alternatively, ip vrf exec command can be used to bind a process with a VRF using some eBPF magic. We can also make upstream contributions and add native VRF support to applications that we need to run inside VRFs, i.e. dnsmasq and radvd (currently neither of these supports VRFs).
Diagram below shows how the separation of network instances using VRFs would look like. For every local/vpn network instance, zedrouter would create a separate VRF (automatically with its own routing table) and put the NI bridge under this VRF device. External processes providing network services separately for each NI, i.e. dnsmasq and radvd (and http server as a go routine of zedbox), would have their sockets bound to the VRF (most likely using 'ip vrf exec'). There will be no VRFs
...
TODO
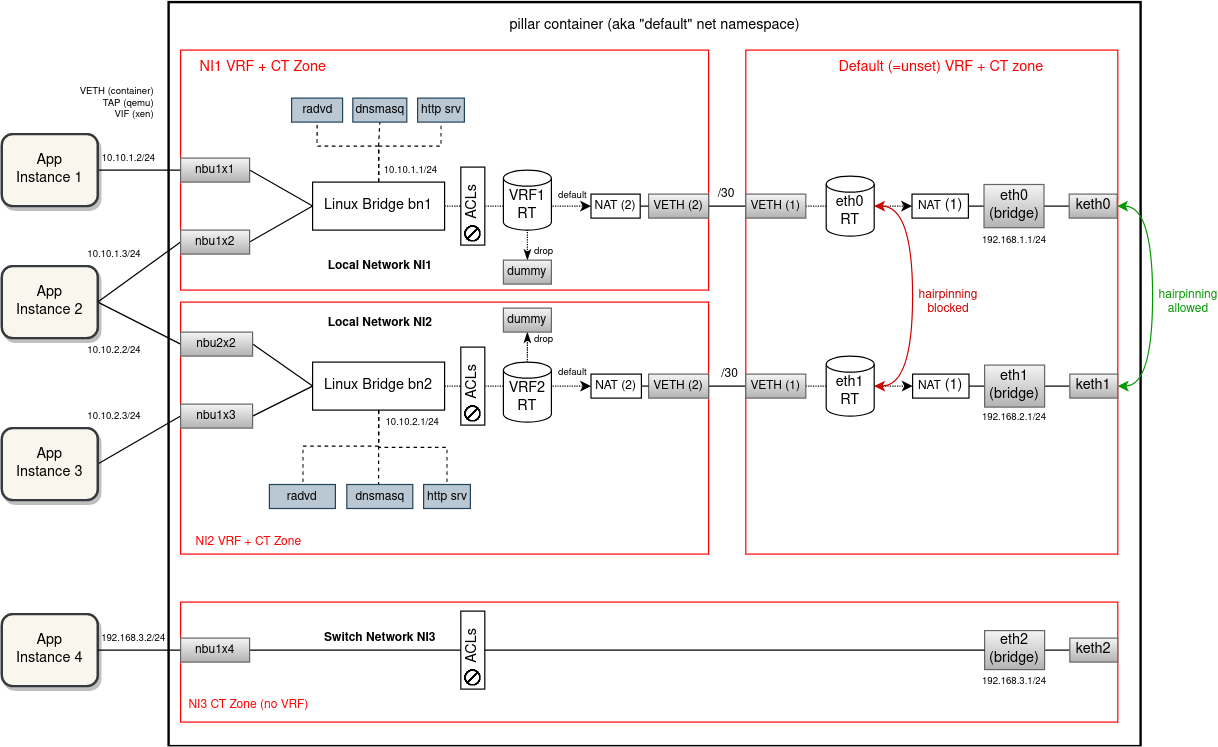
created for switch network instances. From EVE point of view these are L2-only networks.
Uplink interfaces would remain in the default (i.e. not configured) VRF domain and a VETH pair per NI would be used to interconnect the downlink (left) and the uplink (right) side. VETH interface will operate in the L3 mode - it will have IP addresses assigned on both ends from a /30 subnet. What supernet to allocate these subnets from is up to the discussion. It should be selected such that collision with other routed subnets is minimal. Already considered and tested are these special-purpose or reserved subnets: 0.0.0.0/8, 127.0.0.0/8, 169.254.0.0/16 and 240.0.0.0/4. However, only the last two turned out to be routable by Linux network stack without issues.
Because we want to allow network instances to have overlapping IP subnets (between each other and with host networks), packet leaving NI VRF and entering the default VRF has to be S-NATed to the VETH IP. Given the presence of this VETH interface and the NAT rule, packets traveling between applications (deployed in local NIs) and external endpoints will be routed and NATed inside the pillar container twice. Similarly, port mapping ACL rules will have to be implemented as two D-NAT pre-routing rules, one for the uplink interface and the second for the corresponding VETH interface.
There will be no VETH links between VRFs of network instances. The current behavior of applications from different networks not being able to talk to each other directly will be preserved (and enforced with stronger measures). Hairpinning through portmaps will remain as the only option for communication for network-separated applications.
The implementation of ACLs is not going to undergo any significant changes, the existing iptables rules will remain pretty much the same (aside for the two DNAT rules for each portmap). However, using only VRFs is not enough for isolation when NAT and connection marking is being used (for ACLs and flowlog). It is necessary to also separate conntrack entries from different VRF domains. This can be easily accomplished using conntrack zones (conntrack entries split using zone IDs). A NI-specific conntrack (CT) zone is used in-between the bridge and the NI-side of the VETH. For the default routing table (between uplinks and the uplink-side of VETHs) we could leave the default CT zone 0. However, experiments showed that with VRF devices being used the default CT zone stops working correctly, resulting in skipped iptables rules and some strange behaviour. Using any non-zero CT zone seems to fix the issue (see PoC section below).
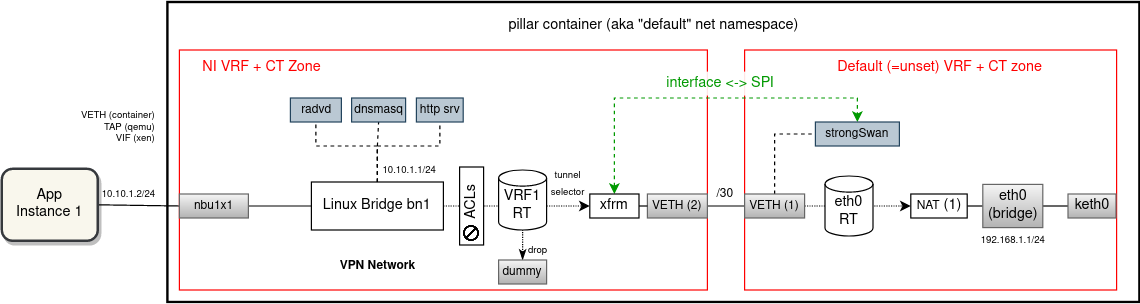
Special attention should be given to VPN networks. For the most part, these networks would be extended with VRFs just like the local network instances. However, for strongSwan (IKE daemon) to operate in multi-VRF mode, we have to switch to Route-based VPN mode. Using special XFRM device (successor to VTI device) it is possible to bind an IPsec tunnel with a VRF domain as shown in the diagram below.
A single strongSwan process will continue operating for all VPN network instances. For every VPN NI there will be a separate XFRM device created inside the NI VRF, linked with the corresponding IPsec connection configuration using XFRM interface ID. Packets sent from applications will be routed by VRF routing table via the associated XFRM device, which then determines which SAs to use for encryption. In the opposite direction, the SPI field will link to the XFRM device and thus the VRF where the decrypted packet should be inserted to for forwarding.
With this, it will be possible to deploy multiple VPN network instances with overlapping traffic selectors and still route/encrypt/decrypt unambiguously.TODO
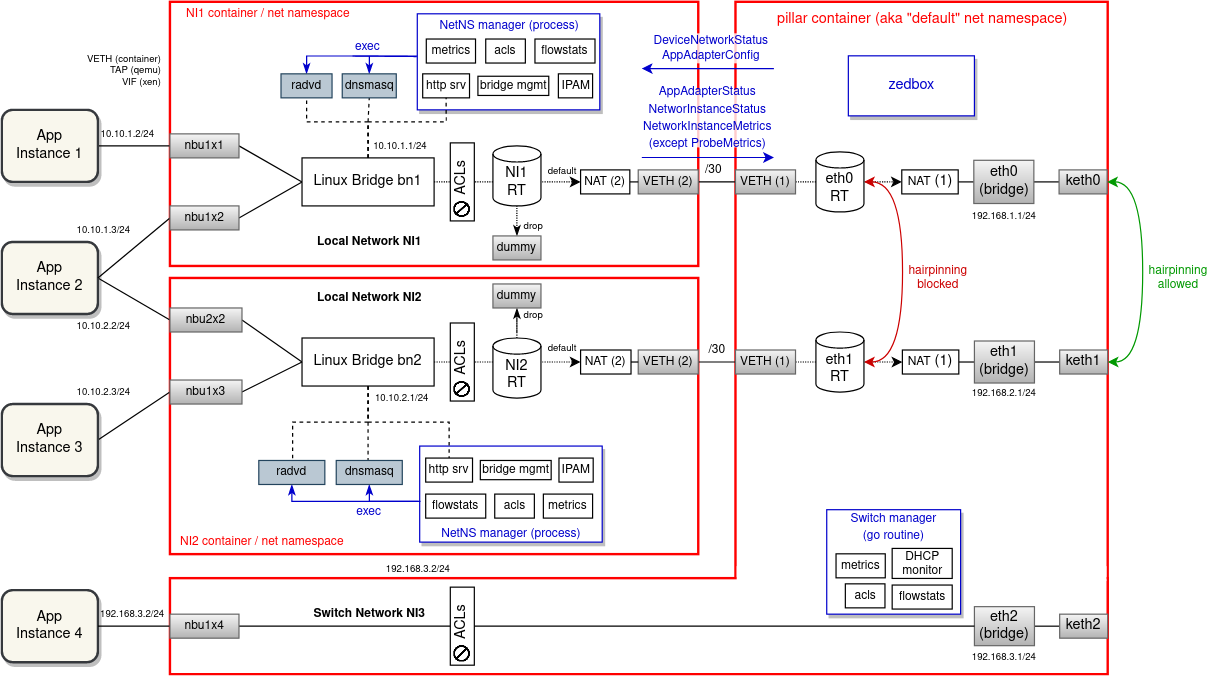
Network Namespaces
TODO
Proof of Concept
...
In order to verify that the proposed network configuration would actually work for all scenarios as intended, a PoC based on docker containers representing network stacks of (mock) apps, network instances and zedbox has been prepared. The source code for the PoC with diagrams and description can be found in this repository: https://github.com/milan-zededa/evenet
The idea was to come up with the simplest scenario (edge device configuration) that exercises all important network use-cases that EVE has to support (i.e. all types of network instances, all possible routing paths, all kinds of ACLs, etc.) and includes some overlapping subnets so that network isolation is a requirement. Then using docker containers we simulate all network stacks present in the scenario and run shell scripts that create the same network configuration that EVE would apply if this proposal was implemented. With this we can quickly and easily validate the proposed network configuration changes before commencing any implementation work in the EVE repository.
The scenario that PoC simulates consists of 6 apps and 6 network instances (3 locals, 2 vpns and 1 switch), with some overlapping subnets and some ACLs defined on top of that. A detailed description of the scenario can be found in the top-level README file of the PoC repository. There is a PoC implementation with VRFs as well as with network namespaces, so that the two proposals can be compared and an informed decision which one to choose can be made.
Both PoCs successfully implement the scenario and pass all devised tests, overcoming the challenge of network IP subnet and VPN traffic selector collisions (see here and here). Notice that tests also cover hairpinning inside and outside the device (which one to do depends on whether src and dst NIs use the same uplink). The reason why preffer to use VRFs is their lower overhead and the fact that they are easier to manage.
For veths, subnets 127.0.0.0/8 and 0.0.0.0/8 sadly failed the validation - routing does not work as expected/desired (even if the local table is tweaked in various ways). On the other hand, 169.254.0.0/16 and 240.0.0.0/4 can be routed between network namespaces and VRFs without issues. But for 169.254.0.0/16 we need to select a subnet that does not contain 169.254.169.254, which is already used for the HTTP server with cloud-init metadata. After some internal discussion, we are more inclined to allocate VETH IPs from the (most likely) forever-reserved Class E subnet 240.0.0.0/4. TODO
Development Steps (VRF Proposal)
...
| No Format |
|---|
PR 1:
Multi-VRF (PR 1): Build Linux kernel with VRF support
= https://www.pivotaltracker.com/story/show/178785411
PR 2:
Multi-VRF (PR 2): LD-PRELOAD library for VRF-unaware processes
= https://www.pivotaltracker.com/story/show/178785483
PR 3:
Multi-VRF (PR 3): Eden test for local networks with overlapping IP subnets
= https://www.pivotaltracker.com/story/show/178785541
PR 4:
Multi-VRF (PR 4): Local & Switch Network instance (Create/Modify/Delete)
= https://www.pivotaltracker.com/story/show/178785641
Multi-VRF (PR 4): ACLs
= https://www.pivotaltracker.com/story/show/178785656
Multi-VRF (PR 4): Flow collection
= https://www.pivotaltracker.com/story/show/178785689
Multi-VRF (PR 4): Network instance metrics
= https://www.pivotaltracker.com/story/show/178785716
PR 5:
Multi-VRF (PR 5): Eden test for VPN networks with overlapping traffic selectors
= https://www.pivotaltracker.com/story/show/178785745
- without VRFs this test will be failing
PR 6:
Multi-VRF (PR 6): VPN Network instance
= https://www.pivotaltracker.com/story/show/178785793 |