Background and Motivation
Currently we keep the EVE device networking and the different network instances for application networking separated using a combination of IP rules (PBR = policy based routing) and ACLs (iptables).
...
We can get better separation, including IP address isolation if we split network instances using either VRFs or with network namespaces. Furthermore, if we use a containerd task to run network instance networking (especially the external processes like dnsmasq, radvd, etc.), we can even isolate resource usage and apply limiting. We will now describe VRFs and network instances separately, with a bit more focus on VRFs, which, after some internal discussion, are now the preferred choice.
VRF Proposal
VRF device combined with IP rules provides the ability to create virtual routing and forwarding domains (aka VRFs, VRF-lite to be specific) in the Linux network stack. VRF essentially provides a light-weight L3-level (and above) isolation, i.e. multiple interfaces can have the same IP address assigned if they are inside different VRF domains and, similarly, multiple processes can listen on the same IP address. Compare that with network namespaces, which provide a full device-level isolation, but at a cost of a higher overhead and with additional challenges for the management plane (see "Network Namespaces" below).
...
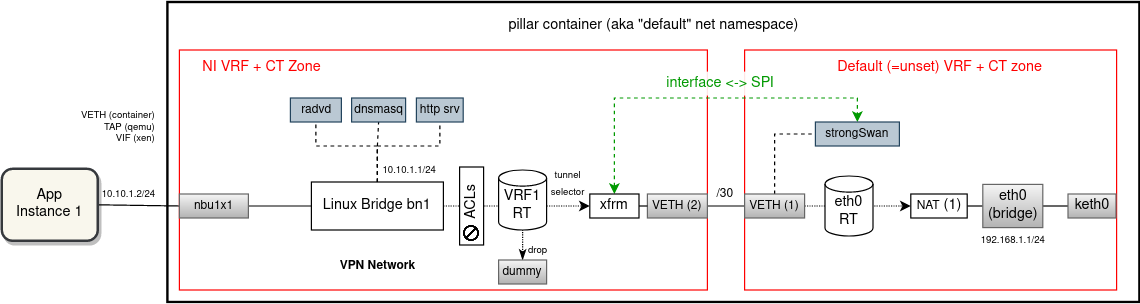
There will be no VETH links between VRFs of network instances. The current behavior of applications from different networks not being able to talk to each other directly will be preserved (and enforced with stronger measures). Hairpinning through portmaps will remain as the only option for communication for network-separated applications. In the default VRF domain there will be one routing table per uplink interface. Using ip rules each network instance will be matched with the RT of the uplink that was selected for that network by the configuration/probing. Network instances that use different uplinks at a given moment will be completely isolated from each other, not even sharing any RT along the routing path. Consequently, connections between uplink-separate separated NIs can only be established by hairpinning outside the edge device (through portmaps).
...
A single strongSwan process will continue operating for all VPN network instances. For every VPN NI there will be a separate XFRM device created inside the NI VRF, linked with the corresponding IPsec connection configuration using XFRM interface ID. Packet sent from application will be routed by the VRF routing table via the associated XFRM device, which then determines which SAs to use for encryption. An encrypted (and encapsulated) packet then continues through the VETH pair into the default VRF domain where it is routed out by the uplink routing tableRT. In the opposite direction, the SPI field of the encrypted packet will link to the XFRM device and thus the VRF where the decrypted packet should be inserted into for forwarding (i.e. VETH is skipped in this direction).
With this, it will be possible to deploy multiple VPN network instances with overlapping traffic selectors and still route/encrypt/decrypt unambiguously.
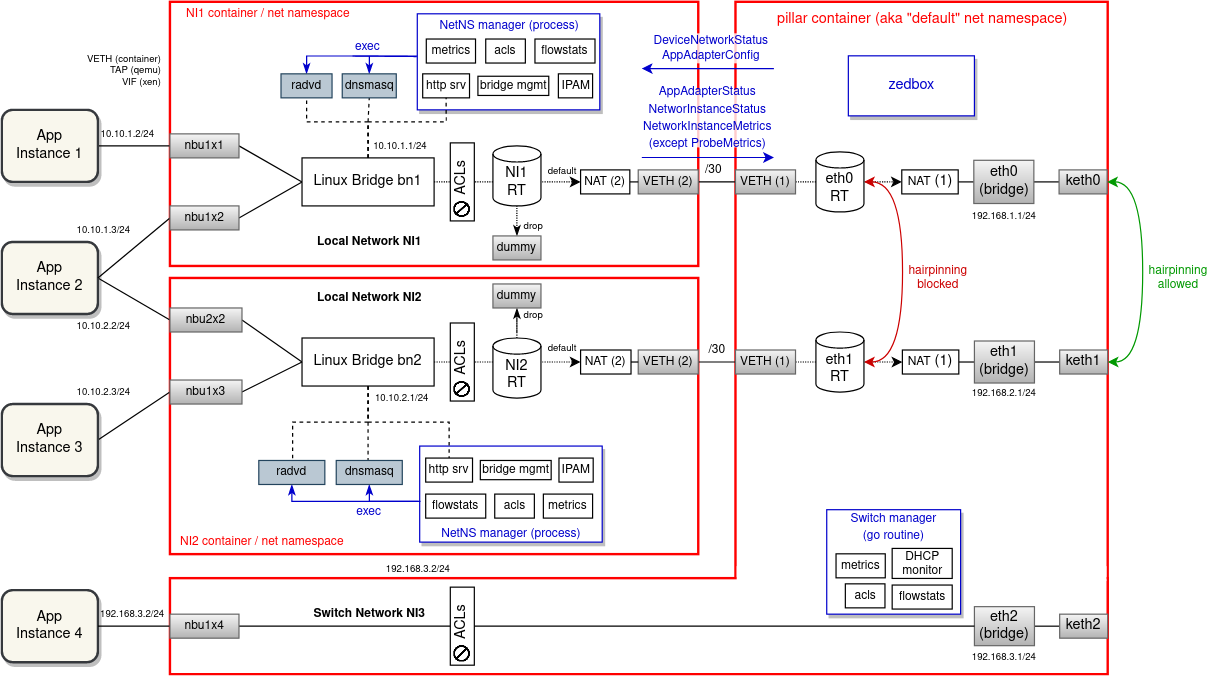
Network Namespaces (alternative proposal)
An alternative solution to VRFs is that instead of using per-NI VRF and CT zone, we could isolate on all network levels and run each Linux bridge and associated network interfaces plus external processes (dnsmasq, radvd, strongSwan ...) in a separate network namespace. For the most part, this is very similar to the VRF proposal, in that both solutions use VETHs to route and NAT packets from/to apps twice. Also, PBR routes/rules and iptables are very much the same, just spread across multiple namespaces.
The advantage of having multiple namespaces is a stronger isolation and not having all routes and iptables crammed in one network stack. Also, this solution is completely transparent to processes (like dnsmasq, radvd, etc.). The major downside of this solution is a higher overhead (memory footprint in particular). Also debugging will be somewhat more difficult. For example, for packet tracing one has to first switch to the proper network namespace or trace packets across multiple namespaces at once.
However, from the management-plane point of view this proposal is considerably more difficult to implement than VRFs. Working with multiple namespaces from the same process (e.g. zedbox) is possible but quite challenging. While each process has its own "default" namespace where it has started, individual threads can be switched between namespaces as needed. However, frequent switching between namespaces adds some overhead and it makes development and debugging even harder than it already is. For this reason, most network-related software products, including strongSwan for example, are intentionally not able to manage multiple network namespaces from a single process instance.
In Golang this is even more challenging since Go routines are provided instead of threads. Because Go routine can travel between threads as it executes, it can potentially change namespace mid-execution. It is possible to lock a Go routine with its current thread, but any Go routine spawned from inside will start back at the process default namespace. This gotcha is nicely described here.
And so while switching to another namespace, locking the thread, doing something quick (not asynchronous, e.g. listing conntracks) and immediately switching back is safe, running a long asynchronous task (e.g. tcp server, packet capture) has the risk of having some Go sub-routines escaping the namespace, which leads to some funky bugs.
In general, it is recommended to spawn a new child process for every network namespace that needs to be operated in. For this reason, this proposal will follow up on the “Bridge Manager” described here.
every new network instance zedrouter would create a new named network namespace (alternatively it could start a new containerd task with its own network namespace), connected with the "default" net namespace using a VETH pair. Downlink interfaces have to be moved into the target network namespace before they are put under the bridge. The bridge part is currently done by hypervisors (veth.sh for containers, qemu & xen allow to specify bridge in the domU config). This would be removed and we would instead finalize downlink interface configuration ourselves in doActivateTail() of domain manager.
For the most part, this is very similar to the VRF proposal, in that both solutions use VETHs to route and NAT packets from/to apps twice. Also, PBR routes/rules and iptables are very much the same, just spread across multiple namespaces.
The advantage of having multiple namespaces is a stronger isolation and not having all routes and iptables crammed in one network stack. Also, this solution is completely transparent to processes (like dnsmasq, radvd, etc.). The major downside of this solution is a higher overhead, in particular the increased memory footprint of the management plane as it is split into multiple processes (see below why it is needed). Also debugging will be somewhat more difficult. For example, for packet tracing one has to first switch to the proper network namespace or trace packets across multiple namespaces at once.
However, from the management-plane point of view this proposal is considerably more difficult to implement than VRFs. Working with multiple namespaces from the same process (e.g. zedbox) is possible but quite challenging. While each process has its own "default" namespace where it has started, individual threads can be switched between namespaces as needed. However, frequent switching between namespaces adds some overhead and it makes development and debugging even harder than it already is. For this reason, most network-related software products, including strongSwan for example, are intentionally not able to manage multiple network namespaces from a single process instance.
In Golang this is even more challenging since Go routines are provided instead of threads. Because Go routine can travel between threads as it executes, it can potentially change namespace mid-execution. It is possible to lock a Go routine with its current thread, but any Go routine spawned from inside will start back at the process default namespace. This gotcha is nicely described here.
And so while switching to another namespace, locking the thread, doing something quick (not asynchronous, e.g. listing conntracks) and immediately switching back is safe, running a long asynchronous task (e.g. tcp server, packet capture) has the risk of having some Go sub-routines escaping the namespace, which leads to some obscure bugs.
In general, it is recommended to spawn a new child process for every network namespace that needs to be operated in. For this reason, this proposal will follow up on the “Bridge Manager” described here.
The main idea of Bridge Manager is to split an overloaded zedrouter and run management of every network instance in a separate Go routine. In this proposal we would go even further and suggest to run Bridge Manager (here called "NetNS manager" because it would manage an entire namespace) as a child process of zedbox (or as a separate containerd task). The main communication mechanism of EVE - pubsub - is already prepared for interprocess messaging.
Splitting the management plane into multiple processes increases overhead and for edge devices the most concerning is the memory footprint. Experimentally, it was estimated that the size of the NetNS binary would be around 22 MB.This was done simply by creating a Go binary importing all packages that are expected to be needed. Please note that this is only a subset of total process RSS. The rest is harder to estimate without fully implementing the NetNS manager. Given that we should support up to 256 network instances, this quickly adds up to hundreds of megabytes of extra memory usageThe main idea of Bridge Manager is to split an overloaded zedrouter and run management of every network instance in a separate Go routine. In this proposal we would go even further and suggest to run Bridge Manager (here called "NetNS manager" because it would manage an entire namespace) as a child process of zedbox (or as a separate containerd process). The main communication mechanism of EVE - pubsub - is already prepared for interprocess messaging.
The following diagram shows how network instances can could be isolated from each other using network namespaces. As it can be seen, not only the network configuration is spread across namespaces, but also the management plane is split into multiple processes (all of which increases complexity and overhead, thus making this proposal less appealing).
Proof of Concept
In order to verify that the proposed network configuration would actually work for all scenarios as intended, a PoC based on docker containers representing network stacks of (mock) apps, network instances and zedbox has been prepared. The source code for the PoC with diagrams and description can be found in this repository: https://github.com/milan-zededa/evenet
...
For VETHs, subnets 127.0.0.0/8 and 0.0.0.0/8 sadly failed the validation - routing does not work as expected/desired (even if the local table is tweaked in various ways). On the other hand, 169.254.0.0/16 and 240.0.0.0/4 can be routed between network namespaces and VRFs without issues. But for 169.254.0.0/16 we need to select a subnet that does not contain 169.254.169.254, which is already used for the HTTP server with cloud-init metadata. After some internal discussion, we are more inclined to allocate VETH IPs from the (most likely) forever-reserved Class E subnet 240.0.0.0/4.
Development Steps (VRF Proposal)
| No Format |
|---|
PR 1: * Build Linux kernel with VRF support = https://www.pivotaltracker.com/story/show/178785411 PR 2: * LD-PRELOAD library for VRF-unaware processes = https://www.pivotaltracker.com/story/show/178785483 - or test 'ip vrf exec' as an alternative PR 3: * Eden test for local networks with overlapping IP subnets = https://www.pivotaltracker.com/story/show/178785541 subnets - without VRFs this test will be failing (i.e. would not be merged until PR 4 is done) PR 4: * Local & Switch Network instance (Create/Modify/Delete) = https://www.pivotaltracker.com/story/show/178785641 * ACLs = https://www.pivotaltracker.com/story/show/178785656 * Flow collection = https://www.pivotaltracker.com/story/show/178785689 collection * Network instance metrics = https://www.pivotaltracker.com/story/show/178785716 PR 5: * Eden test for VPN networks with overlapping traffic selectors = https://www.pivotaltracker.com/story/show/178785745 - without VRFs this test will be failing (i.e. would not be merged until PR 6 is done) PR 6: * VPN Network instance = https://www.pivotaltracker.com/story/show/178785793 |